程序中的错误分为编译时的错误和运行时的错误。编译时的错误主要是语法错误,而运行时的错误则不容易修改,因为其中的错误是不可预料的, 或者可以预料但无法避免的,比如内存空间不够,或者在调用函数时,出现数组越界等错误。我们把程序运行时的错误统称为异常,对异常处理称为异常处理。C++中所提供的异常处理机制结构清晰, 在一定程度上可以保证程序的健壮性。
概述
异常,让一个函数可以在发现自己无法处理的错误时抛出一个异常,希望它的调用者可以直接或者间接处理这个问题。而传统错误处理技术, 检查到一个局部无法处理的问题时:
- 1.终止程序(例如atol,atoi,输入NULL,会产生段错误,导致程序异常退出,如果没有core文件,找问题的人一定会发疯)
- 2.返回一个表示错误的值(很多系统函数都是这样,例如malloc,内存不足,分配失败,返回NULL指针)
- 3.返回一个合法值,让程序处于某种非法的状态(最坑爹的东西,有些第三方库真会这样)
- 4.调用一个预先准备好在出现”错误”的情况下用的函数。
第一种情况是不允许的,无条件终止程序的库无法运用到不能当机的程序里。第二种情况,比较常用,但是有时不合适,例如返回错误码是int, 每个调用都要检查错误值,极不方便,也容易让程序规模加倍(但是要精确控制逻辑,我觉得这种方式不错)。第三种情况,很容易误导调用者, 万一调用者没有去检查全局变量errno或者通过其他方式检查错误,那是一个灾难,而且这种方式在并发的情况下不能很好工作。至于第四种情况, 本人觉得比较少用,而且回调的代码不该多出现。
使用异常,就把错误和处理分开来,由库函数抛出异常,由调用者捕获这个异常,调用者就可以知道程序函数库调用出现错误了,并去处理, 而是否终止程序就把握在调用者手里了。
但是,错误的处理依然是一件很困难的事情,C++的异常机制为程序员提供了一种处理错误的方式,使程序员可以更自然的方式处理错误。
C++ 异常处理过程
C++中处理异常的过程是这样的:在执行程序发生异常,可以不在本函数中处理,而是抛出一个错误信息,把它传递给上一级的函数来解决, 上一级解决不了,再传给其上一级,由其上一级处理。如此逐级上传,直到最高一级还无法处理的话,运行系统会自动调用系统函数 terminate, 由它调用 abort 终止程序(这个过程称之为栈展开)。这样的异常处理方法使得异常引发和处理机制分离,而不在同一个函数中处理。这使得底层函数只需要解决实际的任务, 而不必过多考虑对异常的处理,而把异常处理的任务交给上一层函数去处理。
在栈展开的时候,会退出某个函数,释放当前内存并撤销局部对象,这时会调用对象的析构函数,如果析构函数抛出异常,将会调用标准库 terminate 函数, 强制整个程序非正常退出。所以析构函数应该从不抛出异常。
被调用者抛出异常,调用者(递归向上)处理异常
C++ 异常处理机制组成
C++的异常处理机制有3部分组成:try(检查),throw(抛出),catch(捕获)。把需要检查的语句放在try模块中,检查语句发生错误,throw 抛出异常, 发出错误信息,由 catch 来捕获异常信息,并加以处理。一般 throw 抛出的异常要和 catch 所捕获的异常类型所匹配。异常处理的一般格式为:
try
{
被检查语句
throw 异常
}
catch(异常类型1)
{
进行异常处理的语句1
}
catch(异常类型2)
{
进行异常处理的语句2
}
.
.
.
catch(...) //捕获所有异常处理
{
默认异常处理
}如果在执行try语句模块时,没有发生异常,
则catch语句块不起作用,流程转到其后的语句继续执行。
try
C++ 应用程序中,try 关键字后的代码块中通常放入可能出现异常的代码。随后的 catch 块则可以是一个或者多个;catch 块主要用于异常对应类型的处理。 try 块中代码出现异常可能会对应多种异常处理情况,catch 关键字后的圆括号中则包含着对应类型的参数。
try 块中代码体作为应用程序遵循正常流程执行。一旦该代码体中出现异常操作,会根据操作的判断抛出对应的异常类型。随后逐步的遍历 catch 代码块, 此步骤与 switch 控制结构有点相像。当遍历到对应类型 catch 块时,代码会跳转到对应的异常处理中执行。如果 try 块中代码没有抛出异常, 则程序继续执行下去。
try 体中可以直接抛出异常,
或者在 try 体中调用的函数体中间接的抛出。
throw 抛出异常
C++ 程序中异常抛出是采用关键字 throw 实现的。通常 throw 关键字后会跟随着一个操作数,该操作数可以是一个表达式、 一个 C++ 内置类型数据或者为类类型的对象等。最常见的异常抛出都会放在 try 代码块中。当然,C++ 也允许抛出异常的地方在函数中供 try 块中的代码调用。 正常情况下异常抛出点的定义不要放在 try 块外部无关的地方,因为那样通常会引起编译器默认的终止程序处理。最好的情况下, 异常抛出点直接或者间接的定义在 try 块中。
try 块中可以包含一个或者多个异常抛出点。但是需要注意的是,异常只要一抛出,对应的 catch 块捕捉到后,该 try 块中以下的代码体执行会被终止。 代码执行直接进入对应的 catch 块中,最后 catch 块执行处理完异常后直接跳转至所有当前 try 块对应的 catch 块之后。
catch 匹配
在查找匹配的 catch 期间,找到的 catch 不必是与异常最匹配的那个 catch,相反,将选中第一个找到的可以处理该异常的 catch。因此,在 catch 子句列表中, 最特殊的 catch 必须最先出现,否则没有执行的机会。
进入 catch 的时候,用异常对象初始化 catch 的形参。因为基类的异常说明符可以捕获派生类的异常对象。如果异常对象是引用,则可以使用多态, 调用基类的 virtual 将执行派生类的覆盖的函数。若 catch 的异常说明符是对象,则将派生类对象分割为它的基类对象。
异常匹配除了必须要是严格的类型匹配外,还支持下面几个类型转换.
- 允许从派生类到基类的类型转换
- 允许数组被转换为数组指针,允许函数被转换为函数指针
- 允许非常量到常量的类型转换,
也就是说可以抛出一个非常量类型,然后使用 catch 捕捉对应的常量类型版本
异常处理的一个例子:
#include "stdafx.h"
#include <iostream>
template <typename T>
T Div(T x,T y)
{
if(y==0)
throw y;//抛出异常
return x/y;
}
int main()
{
int x=5,y=1;
double x1=5.5,y1=0.0;
try
{
//被检查的语句
std::cout << x << "/"<< y <<"=" << Div(x,y) << std::endl;
std::cout << x1 << "/" << y1 << "=" << Div(x1,y1) << std::endl;
}
catch(...)//捕获任意类型异常
{
try
{
std::cout << "任意类型异常!"<< std::endl;
throw;//抛出当前处理异常信息给上一层catch
}
catch(int)//异常类型
{
std::cout << "除数为0,计算错误!"<< std::endl;//异常处理语句
}
catch(double)//异常类型
{
std::cout << "除数为0.0,计算错误!" << std::endl;//异常处理语句
}
}
return 0;
}将对象作为
通常,引发异常的函数将传递一个对象。这样做的重要优点是:
- 可以使用不同的异常类型来区分不同函数在不同情况下引发的异常。
- 对象可以携带信息,程序员可以根据这些信息来确定引发异常的原因,同时,catch 块可以根据这些信息来决定采取什么样的措施。
栈解退
现在假设函数由于出现异常(而不是由于返回)而终止,则程序也将释放栈中的内存,但不会在释放栈的第一个返回地址后停止,而是继续释放栈, 直到找到一个位于 try 块中的返回地址。随后,控制权将转到块尾的异常处理程序,而不是函数调用后面的第一条语句。这个过程称为栈解退。 引发机制的一个非常重要的特性是:和函数返回一样,对于栈中的自动类对象,类的析构函数将被调用。
然而,函数返回仅仅处理该函数放在栈中的对象,而 throw 语句则处理 try 块和 throw 之间整个函数调用序列放在栈中的对象。如果没有栈解退这种 特性,则引发异常后,对于中间函数调用放在栈中的自动类对象,其析构函数将不会被调用。
程序进行栈解退以回到能够捕获异常的地方时,
将释放栈中的自动存储型变量,如果变量是类对象,
将为该对象调用析构函数
//error5.cpp -- unwinding the stack
#include <iostream>
#include <cmath> // or math.h, unix users may need -lm flag
#include <string>
#include "exc_mean.h"
class demo
{
private:
std::string word;
public:
demo (const std::string & str)
{
word = str;
std::cout << "demo " << word << " created\n";
}
~demo()
{
std::cout << "demo " << word << " destroyed\n";
}
void show() const
{
std::cout << "demo " << word << " lives!\n";
}
};
// function prototypes
double hmean(double a, double b);
double gmean(double a, double b);
double means(double a, double b);
int main()
{
using std::cout;
using std::cin;
using std::endl;
double x, y, z;
{
demo d1("found in block in main()");
cout << "Enter two numbers: ";
while (cin >> x >> y)
{
try { // start of try block
z = means(x,y);
cout << "The mean mean of " << x << " and " << y
<< " is " << z << endl;
cout << "Enter next pair: ";
} // end of try block
catch (bad_hmean & bg) // start of catch block
{
bg.mesg();
cout << "Try again.\n";
continue;
}
catch (bad_gmean & hg)
{
cout << hg.mesg();
cout << "Values used: " << hg.v1 << ", "
<< hg.v2 << endl;
cout << "Sorry, you don't get to play any more.\n";
break;
} // end of catch block
}
d1.show();
}
cout << "Bye!\n";
// cin.get();
// cin.get();
return 0;
}
double hmean(double a, double b)
{
if (a == -b)
throw bad_hmean(a,b);
return 2.0 * a * b / (a + b);
}
double gmean(double a, double b)
{
if (a < 0 || b < 0)
throw bad_gmean(a,b);
return std::sqrt(a * b);
}
double means(double a, double b)
{
double am, hm, gm;
demo d2("found in means()");
am = (a + b) / 2.0; // arithmetic mean
try
{
hm = hmean(a,b);
gm = gmean(a,b);
}
catch (bad_hmean & bg) // start of catch block
{
bg.mesg();
std::cout << "Caught in means()\n";
throw; // rethrows the exception
}
d2.show();
return (am + hm + gm) / 3.0;
}其他异常特性
虽然 throw-catch 机制类似于函数参数和函数返回机制,但还是有些不同之处。
- 返回的具体位置不同
函数 fun() 中的返回语句将控制权返回到调用 fun() 的函数,但 throw 语句将控制权向上返回到第一个这样的函数:
包含能够捕获相应异常的 try-catch 组合。
- 引发异常时编译器总是创建一个临时拷贝,即使异常规范和 catch 块中指定的是引用,例如:
class problem {...};
...
void super() throw (problem)
{
...
if (oh_no)
[
problem oops; // construct object
throw oops; // throw it
...
]
...
try {
super();
}
catch(problem & p)
{
// statements
}
}p 将指向 oops 的副本而不是 oops 本身。这是件好事,因为函数 super() 执行完毕后, oops 将不复存在。不过如果将引发异常和创建对象组合在一起 将更简单
throw problem();
// construct and throw default problem object
既然返回的是副本,为何代码中使用引用呢?
将引用作为返回值得通常原因是避免创建副本以提高效率。答案是,引用还有另一个重要特征;基类引用可以执行派生类对象。假设有一组通过继承关联 起来的异常类型,则在异常规范中只需列出一个基类引用,它将于任何派生类对象匹配。而且这样是合理的,因为在一般情况下回自动判断将使用的是基类 还是派生类方法。
这意味着 catch 块的排列顺序应该与派生顺序相反
例子如下:
class bad_1 {...};
class bad_2 : public bad_1 {...};
call bad_3 : public bad_2 {...};
...
void duper()
{
...
if (oh_no)
throw bad_1();
if (rats)
throw bad_2();
if (drat)
throw bad_3();
}
...
try {
duper();
}
catch(bad_3 &be)
{
...
}
catch(bad_2 &be)
{
...
}
catch(bad_1 &be)
{
...
}exception 类
本文只是简单介绍 exception 类及其标准异常类,详细学习请查阅 C++ 帮助文件及其中的示例和说明。
C++语言本身或者标准库抛出的异常都是 exception 的子类,称为标准异常(Standard Exception)。你可以通过下面的语句来匹配所有标准异常:
try{
//可能抛出异常的语句
}catch(exception &e){
//处理异常的语句
}exception 类位于
class exception {
public:
exception () throw(); //构造函数
exception (const exception&) throw(); //拷贝构造函数
exception& operator= (const exception&) throw(); //运算符重载
virtual ~exception() throw(); //虚析构函数
virtual const char* what() const throw(); //虚函数
}这里需要说明的是 what() 函数。what() 函数返回一个能识别异常的字符串,正如它的名字“what”一样,可以粗略地告诉你这是什么异常。 不过C++标准并没有规定这个字符串的格式,各个编译器的实现也不同,所以 what() 的返回值仅供参考。
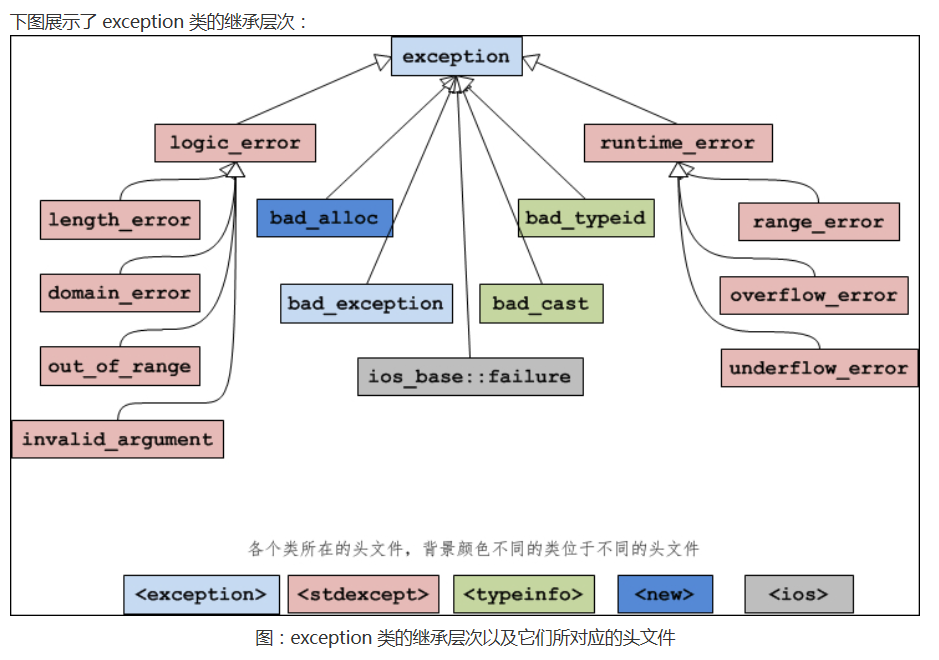


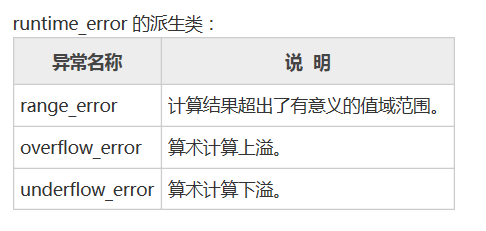
异常何时回迷失方向
如果异常不是在函数中引发(或者函数没有异常规范),则必须捕获它。如果没被捕获(在没有 try 块或没有匹配的 catch 块时,将出现这种情况), 则异常被称为未捕获异常。在默认情况下,这将导致程序异常终止。然而,可以修改程序对意外异常和未捕获异常的反应。
详细列表如下:
- 意外异常:
异常,如果是在带异常规范的函数中引发的,则必须与规范列表里的某个异常匹配,若没有匹配的,则为意外异常,默认情况下,会导致程序异常终止
- 未捕获异常:
异常如果不是在函数中引发的(或者函数没有异常规范),则它必须被捕获。如果没被捕获(没有try块或没有匹配的的catch块),则为未捕获异常。 默认情况下,将导致程序异常终止
修改默认设置
- 未捕获异常:此异常不会导致程序立刻终止
(terminate()、set_terminate() 都在 exception 头文件中声明) 程序首先调用函数 terminate()—-> 默认情况下,terminate()调用 abort()函数, 可以通过 set_terminate() 函数指定 terminate()调用的函数,修改这种行为。
若 set_terminate()函数调用多次,则 terminate()函数将调用最后一次 set_terminate()设置的函数
例如: set_terminate(MyQuit); void MyQuit(){…}
此时若出现未捕获异常,程序将调用 terminate(),而 terminate()将调用 MyQuit()
- 意外异常
发生意外异常时,程序将调用unexcepted()函数—>unexpected()将调用terminate()函数—>terminate()在默认情况下调用abort()函数 可以通过set_unexcepted()函数,修改这种默认行为,但unexpected()函数受限更多
- 1)过terminate()、abort()、exit()终止程序
- 2)引发异常
- 引发的异常与原来的异常规范匹配,则可以用预期的异常取代意外异常
- 引发的异常与原来的异常不匹配,且异常规范中没有包括bad_exception类型(继承自exception类),则程序将调用terminate()
- 引发的异常与原来的异常不匹配,且原来的异常规范中包含了bad_exception类型,则不匹配的异常将被bad_exception异常所取代
总之,如果要不好所有的异常(不管是预期还是意外异常),则可以这样做:
- 确保异常头文件的声明可用:
#include <exception>
using namespace std;- 设计一个替代函数,将意外异常转换为 bad_exception 异常,该函数的原型如下:
void myUnexception()
{
throw std::bad_exception();
// or just throw
}仅适用 throw,而不指定异常将导致重新引发原来的异常。然而,如果异常规范中包含了这种类型,则该异常将被 bad_exception 对象所取代。
- 在程序的开始位置,将意外异常操作指定为调用该函数(原理类似 linux 下的驱动模块入口出口函数):
set_unexcepted(myUnexception);
- 将 bad_exception 类型包括在异常规范中,并添加如下 catch 块序列:
double Argh(double, double) throw(out_of_bounds, bad_exception);
...
tru {
x = Argh(a, b);
}
catch(out_of_bounds & ex)
{
...
}
catch(bad_exception & ex)
{
...
}有关异常的注意事项
应在设计程序时就加入异常处理功能,而不是以后再添加。这样做有些缺点。例如,使用异常会增加程序代码,降低程序运行速度。异常规范不适用于模板, 因为模板函数引发的异常可能随特定的具体化而异。异常和动态分配并非总能协同工作(主要是因为异常捕获后将跳过其后的所有代码,如果 delete 正 好在这个位置,将导致指针被释放但所执行的内存却没有被释放,导致内存泄漏,不过可以在异常处理代码中添加该代码,类似的 JAVA 使用 finally 进行 处理这种情况)
总之,虽然异常处理对于某些项目极为重要,但它也会增加编程的工作量、增大程序、降低程序的速度。另一方面,不进行错误检查的代价可能非常高。 不过个人的建议是,有针对性的进行处理,选择最为严重的最开始进行处理。
要开发优秀的软件,必须花时间了解库和类中的复杂内容,
就像必须花时间学习 C++ 本身一样。
通过库文档和源代码了解到的异常和错误处理细节将
将使程序和他的软件受益。
RTTI(待续)
RTTI(Run Time Type Identification)即通过运行时类型识别,程序能够使用基类的指针或引用来检查着这些指针或引用所指的对象的实际派生类型。
RTTI的常见的使用场合
- 异常处理(exceptions handling)、
- 动态转类型(dynamic casting) 、
- 模块集成、
- 对象I/O 。
等用到以上场合时在完成“待续”。
RTTI机制的产生
为什么会出现 RTTI 这一机制,
这和 C++ 语言本身有关系。和很多其他语言一样,C++ 是一种静态类型语言。其数据类型是在编译期就确定的, 不能在运行时更改。然而由于面向对象程序设计中多态性的要求,C++ 中的指针或引用(Reference)本身的类型, 可能与它实际代表(指向或引用)的类型并不一致。有时我们需要将一个多态指针转换为其实际指向对象的类型,就需要知道运行时的类型信息, 这就产生了运行时类型识别的要求。
和 Java 相比,C++ 要想获得运行时类型信息,只能通过 RTTI 机制,并且 C++ 最终生成的代码是直接与机器相关的。 我对 Java 的运行时类型识别不是很熟悉,所以查了一下相关资料:Java 中任何一个类都可以通过反射机制来获取类的基本信息(接口、父类、方法、 属性、Annotation 等),而且 Java 中还提供了一个关键字,可以在运行时判断一个类是不是另一个类的子类或者是该类的对象,Java 可以生成字节码文件, 再由 JVM(Java虚拟机)加载运行,字节码文件中可以含有类的信息。
【注意】本文属于作者原创,欢迎转载!转载时请注明以下内容:
(转载自)ShengChangJian's Blog编程技术文章地址:
https://ShengChangJian.github.io/2016/09/C++-Exception.html
主页地址:https://shengchangjian.github.io/